题目简评
join-tables
- 实现
INNER JOIN功能,需要支持join多张表。 - 当前已经支持多表查询的功能,需要考虑 数据量比较大时 如何处理。
SELECT * FROM JOIN_TABLE_LARGE_1 INNER JOIN JOIN_TABLE_LARGE_2 ON JOIN_TABLE_LARGE_1.ID=JOIN_TABLE_LARGE_2.ID INNER JOIN JOIN_TABLE_LARGE_3 ON JOIN_TABLE_LARGE_1.ID=JOIN_TABLE_LARGE_3.ID INNER JOIN JOIN_TABLE_LARGE_4 ON JOIN_TABLE_LARGE_3.ID=JOIN_TABLE_LARGE_4.ID INNER JOIN JOIN_TABLE_LARGE_5 ON 1=1 INNER JOIN JOIN_TABLE_LARGE_6 ON JOIN_TABLE_LARGE_5.ID=JOIN_TABLE_LARGE_6.ID WHERE JOIN_TABLE_LARGE_3.NUM3 < 10 AND JOIN_TABLE_LARGE_5.NUM5 > 90;其中 sql INNER JOIN JOIN_TABLE_LARGE_5 ON 1=1这句筛选会将表中 所有数据行 和之前的结果做笛卡尔积, 之后 再 在 WHERE 中进行筛选. 这一过程中会产生极大量的中间数据 (超100,000行), MiniOB的性能优化难以处理这种量级.
SELECT * FROM JOIN_TABLE_LARGE_1 INNER JOIN JOIN_TABLE_LARGE_2 ON JOIN_TABLE_LARGE_1.ID=JOIN_TABLE_LARGE_2.ID INNER JOIN JOIN_TABLE_LARGE_3 ON JOIN_TABLE_LARGE_1.ID=JOIN_TABLE_LARGE_3.ID AND JOIN_TABLE_LARGE_3.NUM3 < 10 INNER JOIN JOIN_TABLE_LARGE_4 ON JOIN_TABLE_LARGE_3.ID=JOIN_TABLE_LARGE_4.ID INNER JOIN JOIN_TABLE_LARGE_5 ON JOIN_TABLE_LARGE_5.NUM5 > 90 INNER JOIN JOIN_TABLE_LARGE_6 ON JOIN_TABLE_LARGE_5.ID=JOIN_TABLE_LARGE_6.ID;为此我们重写了optimizer里的PredictPushdownRewriter这一优化器, 遍历WHERE字句中的所有条件判断, 将尽可能多的判断表达式 下推 到深层的TableScan和Join Operator中, 尽早将不符合条件的行筛出, 减小中间生成行的数量.
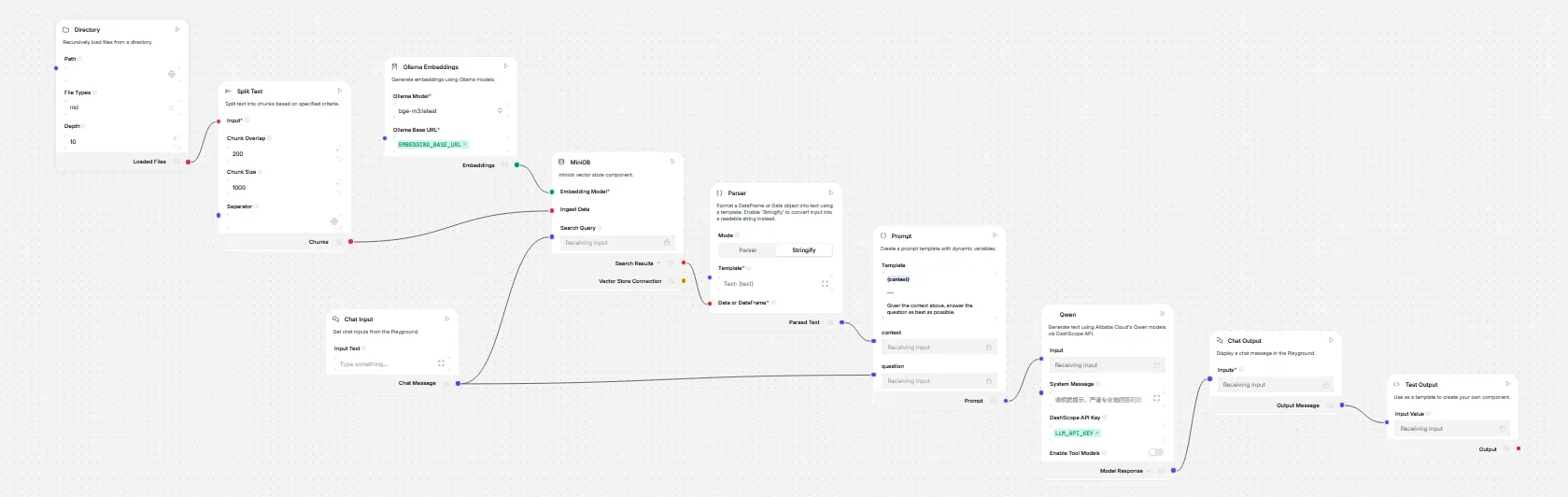
在完善PredictPushdownRewriter之后, 执行sql EXPLAIN命令查看PhysicalOperator执行计划, 可以看到Predict节点被 尽可能下推 到TableScan表扫描和Join笛卡尔积Operator之后.
Query PlanOPERATOR(NAME)PROJECT└─ PREDICATE └─ NESTED_LOOP_JOIN ├─ NESTED_LOOP_JOIN │ ├─ PREDICATE │ │ └─ NESTED_LOOP_JOIN │ │ ├─ PREDICATE │ │ │ └─ NESTED_LOOP_JOIN │ │ │ ├─ PREDICATE │ │ │ │ └─ NESTED_LOOP_JOIN │ │ │ │ ├─ TABLE_SCAN(JOIN_TABLE_LARGE_1) │ │ │ │ └─ TABLE_SCAN(JOIN_TABLE_LARGE_2) │ │ │ └─ PREDICATE │ │ │ └─ TABLE_SCAN(JOIN_TABLE_LARGE_3) │ │ └─ TABLE_SCAN(JOIN_TABLE_LARGE_4) │ └─ PREDICATE │ └─ TABLE_SCAN(JOIN_TABLE_LARGE_5) └─ TABLE_SCAN(JOIN_TABLE_LARGE_6)- 注意带有多条
on条件的join操作。 - 注意 隐式内连接 和
INNER JOIN混合的情况。
SELECT * FROM A, B INNER JOIN C ON B.id = C.b_id;expression
实现表达式功能。这里的表达式仅考虑算数表达式,可以参考现有实现的 calc 语句,可以参考 表达式解析 ,在 SELECT 语句中实现。如果有些表达式运算结果有疑问,可以在 MySQL 中执行相应的 SQL,然后参考 MySQL 的执行即可。比如一个数字除以 0,应该按照NULL 类型的数字来处理。
由于MiniOB已经实现了 CALC 语句, 其中基本已经实现了绝大部分expression计算需要的代码. 因此将需要expression进行运算的语句, 例如WHERE语句中的条件替换为expression, 即可基本通过测试.
function
实现一些常见的函数,包括
length、round和date_format。
函数的语法解析实际上和MiniOB中已为我们实现好的SUM 聚合函数的解析基本一致 , 于是直接把解析聚合函数的语法解析器改成解析UnboundedFunction语句, 然后在FunctionBinder中根据函数名进行进一步的判断, 绑定为FunctionExpr或AggregateExpr.
multi-index
多字段索引功能。即一个索引中同时关联了多个字段。此功能除了需要修改语法分析,还需要调整 B+ 树相关的实现。
通过扩展原来的索引B+树实现:
- 单字段变量改成用
std::vector存多字段 - 接口扩展
- 适配多字段的比较
- 多字段的页面容量计算
直接限制为支持 有限个字段 ,比较好通过
unique
实现支持多列的唯一索引功能。唯一索引是指一个索引上的数据都不是重复的。支持使用简单的 SQL 创建索引。需要考虑数据插入、数据更新等场景。
通过传递一个is_unique参数来判断是否需要检查重复,在INSERT时进行判定。
问题点:
NULL不算重复,不影响UNIQUE- 需要实现
DROP INDEX - 遇到了
UPDATE的事务问题,进行了一些重构。UPDATE就简化成先DELETE旧数据再INSERT新数据
吐槽点:
UPDATE在这道题需要 支持一条语句SET多条语句 ,找半天问题没想到是这里…
(这种就不能UPDATE那题就要求好吗)
group-by
分组功能按照一定条件进行分组,目的是为了方便用户查询数据结果,分析数据。按照一个或多个字段对查询结果分组,需要支持
HAVING子句用于筛选分组后的数据,因为聚合函数不能出现在WHERE后面。
MiniOB的原始代码已经为我们写好了GROUP BY的LogicalOperator和PhysicalOperator, 我们主要要做的是HAVING的处理.
由于HAVING基本逻辑和WHERE一致, 可 直接重用 PredictPhysicalOperator, 只需要修改关于聚合函数的合法性判断即可.
simple-sub-query
- 支持简单的
IN(NOT IN) 语句,注意NOT IN语句面对NULL时的特殊性。
IN语句不会受到NULL值影响, 而NOT IN在遇到NULL值时 直接返回 FALSE值.
- 支持与子查询结果做比较运算。注意子查询结果为多行的情况。
子查询结果为多行时, 返回RC::SUBQUERY_MULTI_ROWS的自定义错误.
-
支持子查询中带聚合函数。
-
子查询中不会与主查询做关联。这也是简单子查询区分于复杂子查询的地方。
此乃谎言.
SELECT * FROM TABLE_ALIAS_1 T1 WHERE ID IN (SELECT T2.ID FROM TABLE_ALIAS_2 T2 WHERE T2.COL2 >= T1.COL1);这句查询中存在别名的共享, 子查询使用了主查询中定义的别名 T1.
- 表达式中可能存在不同类型值比较。
子查询最主要的难点在于, SelectStmt解析时并不支持嵌套, 而且作为Stmt来嵌套对后续进行运算也很麻烦. 相对来说更简单的方法是将 整个子查询看作一个SubqueryExpr , 和其他的表达式一样进行从上到下的求值, 从下到上的返回.
在ExpressionBinder中, SubqueryExpr需要根据语法解析得到的SqlNode生成SelectStmt, 而在表达式求值时对SubqueryExpr额外执行open()和close()操作来读取数据文件.
alias
别名基本没什么问题, 主要是子查询中外部别名需要传入.
为实现子查询和主查询之间 别名的关联 , 我们修改了SelectStmt的初始化, 将外部查询Context传入SelectStmt中, 实现别名的传入.
另外需要支持ALIAS DOT STAREXPR 和STAREXPR AS ALIAS的语法格式, 例如
SELECT T1.ID AS NUM, T1.COL1 AS AGE, T1.FEAT1, T2.* FROM TABLE_ALIAS_1 T1, TABLE_ALIAS_2 T2 WHERE T1.ID < T2.ID;
SELECT * AS ALIAS FROM TABLE_ALIAS_1 T1;null
NULL值 和任何值比较 结果都是FALSE.
主要难点是如何储存NULL值. 借鉴的往年代码使用了每个字段的长度多一位, 用于储存该字段是否为NULL. 虽然MiniOB不需要考虑储存的高效与否, 但是通过指针偏移来读取NULL值状态的方法过于邪恶, 难以调试.
我们采用了常规数据库里使用的 Bitmap 方式来储存NULL值状态. 每一行的最后有一段整字节长度的Bitmap, 其中每一位 对应字段的NULL值状态 . 读取数据表时, 先根据TableMeta计算每一个NULLABLE字段的NullBitmapIndex, 然后在读取时根据Index在Bitmap中查询NULL值状态.
吐槽:
- NULL需要支持UPDATE的子查询(而子查询那道题却没有要求)
- NULL也需要通过刷脸来过掉一些不明问题的用例
union
UNION操作符用于连接两个以上的SELECT语句的结果组合到一个结果集合,并去除重复的行,而UNION ALL不去除重复行。
相对来说还比较简单, 需要为Union和UnionAll分别新建LogicalOperator和PhysicalOperator, 在PhysicalOperator中 缓存下方回传的查询结果Tuple 来进行合并和去重.
由于MiniOB不禁止使用STL, 所以去重只需要将Tuple存入cpp std::set中即可.
order-by
ORDER BY和UNION差别不大, 同样新建LogicalOperator和PhysicalOperator, 然后在PhysicalOperator中将Tuple存入cpp std::priority_queue中即可.
遇到比较坑的问题是, Operator.current_tuple() 返回的指针永远指向同一个地址, 不能只储存这个指针, 而是需要实现 Tuple.copy() 复制对象, 实现数据持久化.
vector-basic/search
-
支持创建包含向量类型的表。
-
支持插入向量类型的记录, 实现距离表达式计算。 支持
COSINE/EUCLIDEAN/DOT三种距离计算方式 -
需要在没有索引的场景下,支持向量检索功能(即精确检索)。
SELECT ID FROM TAB_VEC ORDER BY DISTANCE(B, STRING_TO_VECTOR('[10, 0.0, 5.0]'), 'EUCLIDEAN') LIMIT 1;没什么坑,正常定义一套VECTOR的新类型就可以,注意 向量维度不匹配 时需要返回FAILURE. 需要新实现LIMIT语句,也不难。
text
text字段的最大长度为 65,535 个字节,除了需要实现语法解析,还需要考虑如何在存储引擎中存放超长字段,以支持超过一页的数据。
TEXT类型采用分离存储的设计模式,内部只存引用(占用8字节),实际文本内容存在外部文件中。
struct TextData { char *str; // 指向文本数据的指针 size_t len; // 文本数据的长度 size_t offset; // 在文本文件中的偏移量};唯一提测坑点:测试的文本很长,所以MAX_MEM_BUFFER_SIZE(obclient的传输支持大小)需要开大一点(我直接把8192乘了1024就过了)
alter
ALTER命令允许你添加、修改或删除数据库对象,并且可以用于更改表的列定义、添加约束、创建和删除索引等操作。
题目说仅需要支持四种语句:
ALTER TABLE alter_table_1 ADD COLUMN col INT;ALTER TABLE alter_table_1 DROP COLUMN col;ALTER TABLE alter_table_1 CHANGE COLUMN col id INT;ALTER TABLE alter_table_1 RENAME TO alter_table_2;但是后面的全文索引里ALTER又需要支持
ALTER TABLE texts ADD FULLTEXT INDEX idx_texts_jieba (content) WITH PARSER jieba;咱就不能一次把要求提完?
核心思路:先修改元数据→更新具体数据→持久化
- 要注意NULL位图的处理、change新旧字段名相同是SUCCESS情况
update-mvcc
事务是数据库的基本功能,此功能希望同学们补充 MVCC(多版本并发控制)的 update 功能。这里主要考察不同连接同时操作数据库表时的问题。
实现UNIQUE就自动好了**. **
其实UNIQUE还没AC这道题就好了,最友好的30分。
complex-sub-query
复杂子查询中子查询中会跟父查询联动, 需要支持
EXISTS(NOT EXISTS) 语句。
关联父查询可以通过表达式求值子查询SubqueryExpr.open()时传入父查询的Tuple, 然后实现PhysicalOperator.set_parent_tuple()方法, 使得子查询执行时能够查询到父查询中的值.
支持EXISTS和NOT EXISTS运算符和IN / NOT IN运算符基本一致, 需要注意的是EXISTS运算符是 单目运算符 , 语法解析和表达式绑定时需要一定特殊处理.
create-view
视图,顾名思义,就是一个能够自动执行查询语句的虚拟表。
不过视图功能也非常复杂,需要考虑视图更新时如果更新实体表。
如果视图对应了单张表,并且没有虚拟字段,更新视图,即更新了实体表。
如果实体表中某些字段不在视图中,那此字段的结果应该是 NULL 或默认值。如果视图中包含虚拟字段,比如通过聚合查询的结果,或者视图关联了多张表,他的更新规则就变得复杂起来。
要实现视图的增删改查、多表逻辑、还要嵌套和聚合函数,各种corner case。。
在还有两天截止时开始尝试,到最后一天发现确实做不完就, 反正分够了 摆了.
big-order-by
在内存有限的情况下,实现大数据量的排序,需要优化内存使用。有四张表,每张表有20个字段,数据量在20左右,所有表在一起做笛卡尔积查询,并且对每个字段都会做
ORDER BY排序。
之前ORDER BY用std::priority_queue偷的懒不得不还回来了. 但是 GPT-5-Codex写的外部排序 一次性过了提测.
full-text-index
全文索引(Full-Text Search)是一种用于在大量文本数据中进行高效搜索的技术。它通过基于相似度的查询,而不是精确数值比较,来查找文本中的相关信息。相比于使用 LIKE + % 的模糊匹配,全文索引在处理大量数据时速度更快。
ALTER TABLE texts ADD FULLTEXT INDEX idx_texts_jieba (content) WITH PARSER jieba;
SELECT id, content, MATCH(content) AGAINST('你好') AS score FROM texts WHERE MATCH(content) AGAINST('你好') > 0 ORDER BY MATCH(content) AGAINST('你好') DESC, id ASC;需要支持ALTER添加全文索引、支持WITH PARSER和MATCH AGAINST来实现相关功能。
利用BM25算法完成倒排索引,在插入和删除数据时更新相关统计信息。
- 分词与预处理:利用cppjieba完成分词,并去除停用词。定义一个新的
TOKENIZE类型来实现。
问题:直接这样提测,查询会无法响应结果!
-
分词结果缓存
- 想法很简单,就是把每条数据的 分词结果缓存起来 ,防止重复分词耽误时间
- 利用
std::unordered_map哈希表存储分词结果 - 查询时不需要再进行分词,可以秒出结果,本题PASS。
吐槽
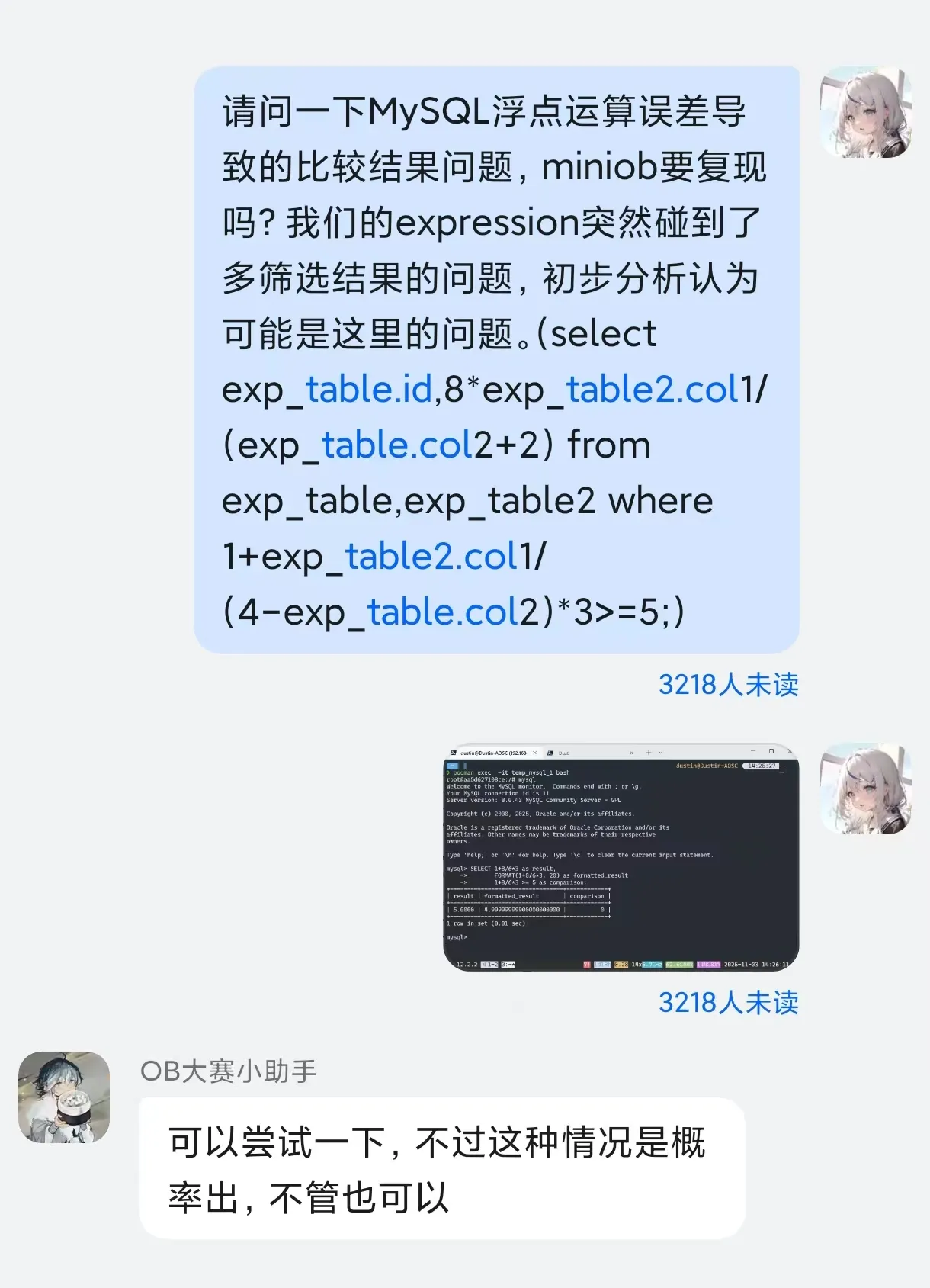
浮点数问题
MySQL存在浮点数计算误差问题, 一些情况下会出现WHERE子句的筛选结果数量少于预期.
例如, SELECT 1 FROM TABLE WHERE 8/6*3+1 >= 5;这句查询, 在MySQL中会因为浮点计算误差得到空结果.
但是MiniOB的测试样例大概是根据MySQL的执行结果生成的, 因此部分测试项目 (例如expression和null) 会有概率随机到不正确的样例而不能通过.
来MiniOB里抽卡来了.
没有OR能430分
这扯不扯.
附加题:RAG这是咋就过了
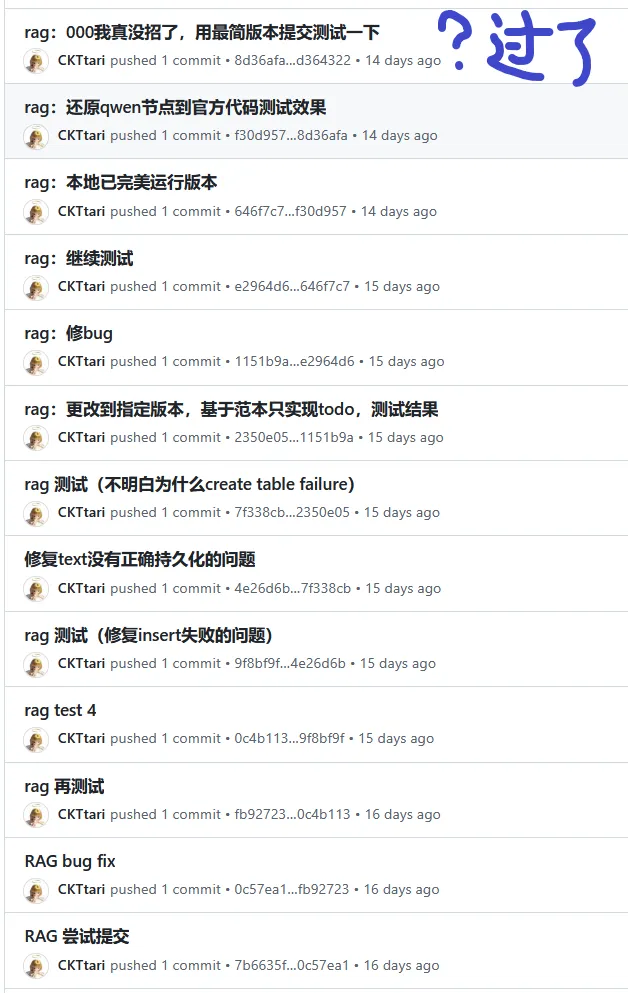
要求:用langflow+miniob,搭配千问和BGE-M3等模型实现一个rag流程,达到一定正确率即可通过。
我正经在本地跑通了RAG流程,但是提交上去都是000这个啥信息也没有的报错
为了定位问题我交了一个最简的input→LLM→output的版本不带任何其他功能
?30分了?分都给我了那还说啥呢。